
By George Pirocanac
I have often been asked, “What is the most memorable bug that you have encountered in your testing career?” For me, it is hands down a bug that happened quite a few years ago. I was leading an Engineering Productivity team that supported Google App Engine. At that time App Engine was still in its early stages, and there were many challenges associated with testing rapidly evolving features. Our testing frameworks and processes were also evolving, so it was an exciting time to be on the team.
What makes this bug so memorable is that I spent so much time developing a comprehensive suite of test scenarios, yet a failure occurred during such an obvious use case that it left me shaking my head and wondering how I had missed it. Even with many years of testing experience it can be very humbling to construct scenarios that adequately mirror what will happen in the field.
I’ll try to provide enough background for the reader to play along and see if they can determine the anomalous scenario. As a further hint, the problem resulted from the interaction of two App Engine features, so I like calling this story A Tale of Two Features.
Feature 1 – Datastore Admin (backup, restore, delete)
Google App Engine was released 13 years ago as Google’s first Cloud product. It allowed users to build and deploy highly scalable web applications in the Cloud. To support this, it had its own scalable database called the Datastore. An administration console allowed users to manage the application and its Datastore through a web interface. Users wrote applications that consisted of request handlers that App Engine invoked according to the URL that was specified. The handlers could call App Engine services like Datastore through a remote procedure call (RPC) mechanism. Figure 1 illustrates this flow.

The first feature in this Tale of Two Features resided in the administration console, providing the ability to back up, restore, and delete selected or all of an application’s entities in the Datastore. It was implemented in a clever way that incorporated it directly into the application, rather than as an independent utility. As part of the application it could freely operate on the Datastore and incur the same billing charges as other datastore operations within the application. When the feature was invoked, traffic would be sent to its handler and the application would process it. Figure 2 illustrates this request flow.
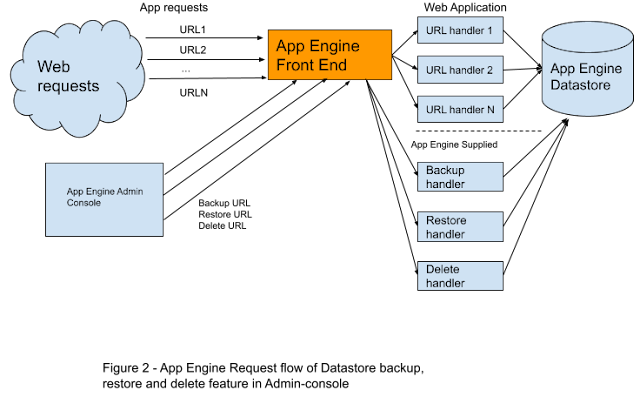
By the time this memorable bug occurred, this Datastore administration feature was mature, well tested, and stable. No changes were being made to it.
Feature 2 – Utilities for Migrating to the HR – Datastore
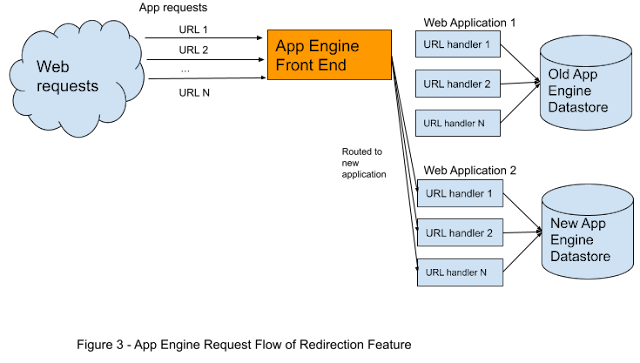
The second feature (or more accurately, set of features) came at least a year after the first feature was released and stable. It helped users migrate their applications to a new High Replication (HR) Datastore. The HR Datastore was more reliable than its predecessor, but using it meant creating a new application and copying over all the data from the old Datastore. To support such migrations, App Engine developers added two new features to the administration console. The first copied all the data from the Datastore of one application to another, and the second redirected all traffic from one application to another. The latter was particularly useful because it meant the new application would seamlessly receive the traffic after a migration. This set of features was written by another team, and we in Engineering Productivity supported them by creating processes for testing various Datastore migrations. The migration-support features were thoroughly tested and released to developers. Figure 3 illustrates the request flow of the redirection feature.
What Could Possibly Go Wrong?
So this was the situation when we released these utilities for migrating to the new Datastore. We were very confident that they worked, as we had tested migrations of many different types and sizes of Datastore entities. We had also tested that a migration could be interrupted without data loss. All checked out fine. I was confident that this new feature would work, yet soon after we released it, we started getting problem reports.
If you have been playing along, now is the time to ask yourself, “What could possibly go wrong?” As an added hint, the problem reports claimed that all the data in the newly migrated application was disappearing.
What Did Go Wrong
As mentioned above, developers began to report that data was disappearing from their newly migrated applications. It wasn’t at all common, yet of course it is most disconcerting when data “just disappears.” We had to investigate how this could occur. Our standard processes ensured that we had internal backups of the data, which were promptly restored. In parallel we tried to reproduce the problem, but we couldn’t—at least until we figured out what was happening. As I mentioned earlier, once we understood it, it was quite obvious, but that only made it all the more painful that we missed it.
What was happening was that, after migrating and automatically redirecting traffic to the new application, a number of customers thought they still needed to delete the data from their old application, so they used the first Datastore admin feature to do that. As expected, the feature sent traffic to that application to delete the entities from the Datastore. But that traffic was now being automatically redirected to the new application, and voila—all the data that had been copied earlier was now deleted there. Since only a handful of developers tried to delete the data from their old applications, this explained why the problem occurred only rarely. Figure 4 illustrates this request flow.
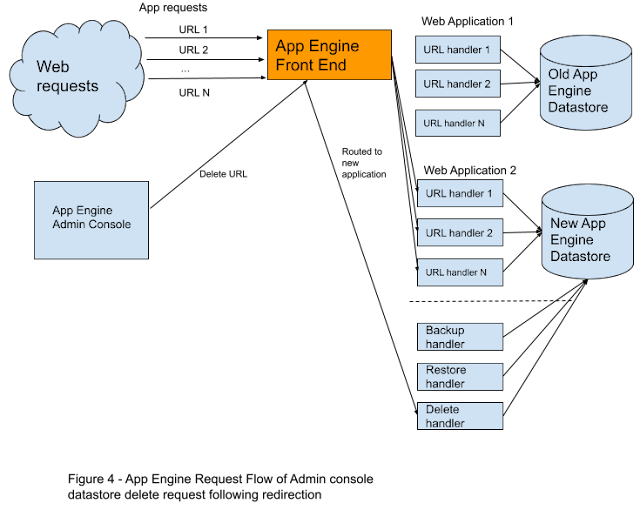
Obvious, isn’t it, once you know what is happening.
Lessons Learned
This all occurred years ago, and App Engine is based on a far different and more robust framework today. Datastore migrations are but a memory from the past, yet this experience made a great impression on me.
The most important thing I learned from this experience is that, while it is important to test features for their functionality, it’s also important to think of them as part of workflows. In performing our testing we exercised a very limited number of steps in the migration process workflow and omitted a very reasonable step at the end: trying to delete the data from the old application. Our focus was in testing the variability of contents in the Datastore rather than different steps in the migration process. It was this focus that kept our eyes away from the relatively obvious failure case.
Another thing I learned was that this bug might have been caught if the developer of the first feature had been in the design review for the second set of migration features (particularly the feature that automatically redirects traffic). Unfortunately, that person had already joined a new team. A key step in reducing bugs can occur at the design stage if “what-if” questions are being asked.
Finally, I was enormously impressed that we were able to recover so quickly. Protecting against data loss is one of the most important aspects of Cloud management, and being able to recover from mistakes is at least as important as trying to prevent them. I have the utmost respect for my coworkers in Site Reliability Engineering (SRE).